Beautiful Soup을 사용하여 네이트의 오늘의 판의 게시물 목록을 긁어오기를 해보자.
https://pann.nate.com/today/view/20210718
관심 있는 부분은 div tag의 class가 bridge_talk 부분이다. 이에 해당하는 부분이 '오늘의 톡'과 '오늘의 엔터'인데 그냥 다 긁어 오자. 나눌 필요가 있으신 부분 알아서 ㅎ

각 게시물의 링크와 제목은 아래와 같다. a tag이며 href 형식이 "/talk/"로 시작하며 뒷부분은 숫자로 되어 있다.

그럼 시작하자.
1) 아래와 같이 '오늘의 판' 주소를 request하여 결과를 받는다.
import re
import requests
from bs4 import BeautifulSoup
url = 'https://pann.nate.com/today/view/20210718'
response = requests.get(url)
if response.status_code == 200:
html = response.text
# ...
else :
print(response.status_code)
2) 받은 결과를 BeautifulSoup에 넣어 파싱한다.
3) class 값이 bridge_talk인 것을 먼저 추린다.
4) 각각에 대해 a tag를 찾아 href 값이 "/talk/1234123432"와 같은 형태를 찾는다.
soup = BeautifulSoup(html, 'html.parser')
_div = soup.body.find_all("div", class_="bridge_talk")
for i in _div:
_a = i.find_all("a")
for j in _a:
if j.has_attr('href') and re.match(r'\/talk\/[0-9]*', j.attrs['href']):
print(f"----> : {j.attrs['href']} - {j.attrs['title']}")
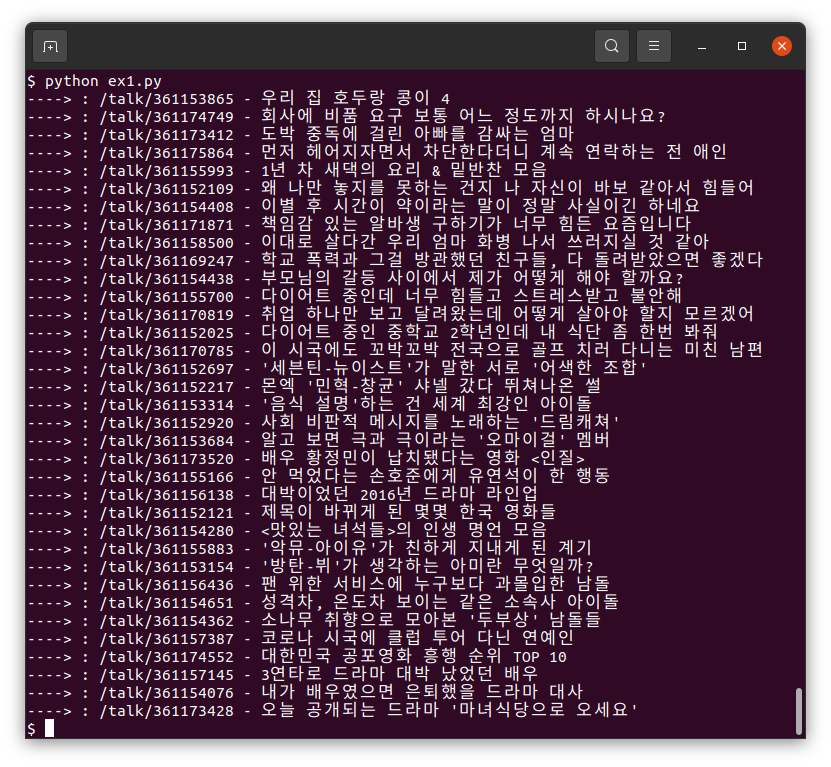
5) 실행 결과를 확인한다.
몇 줄 안 되는 소스코드로 쉽게 결과를 얻을 수 있다.
전체 소스 코드
import re
import requests
from bs4 import BeautifulSoup
url = 'https://pann.nate.com/today/view/20210718'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
_div = soup.body.find_all("div", class_="bridge_talk")
for i in _div:
_a = i.find_all("a")
for j in _a:
if j.has_attr('href') and re.match(r'\/talk\/[0-9]*', j.attrs['href']):
print(f"----> : {j.attrs['href']} - {j.attrs['title']}")
else :
print(response.status_code)
'놀기 > Python' 카테고리의 다른 글
| map function 안에서 문자열 strip 및 replace 하기 (0) | 2021.07.26 |
|---|---|
| Beautiful Soup 설치 및 기본 사용법 (Ubuntu 20.04 기준) (0) | 2021.07.19 |

댓글